(2019-02-22 初稿 - 2021-05-21 転記・修正 )
はじめに
CQ出版社のインターフェース(2018年3月号)に、「遺伝条件を設定して突然変異も起こさせる発展形【遺伝的プログラミング」(牧野 浩二、小林裕之 著)】が掲載されていた。以前、遺伝的アルゴリズムでナップサック問題に挑戦したことがあるので、この記事がとても読みやかったとともに、自分でもプログラミングしてみたくなった。
記事に掲載されたプログラムのダウンロードは以下のページからできるので、2018年3月号のところからダウンロードし試してみて。
上記プログラムは、JAVAで記述されており、自分自身の勉強のためにも、rubyでスクリプトを作成してみた。
(2021-05-21 追記)
PythonでTree構造を操作するバージョンを作ろうとしているが、いつまで経ってもできないヘタレな筆者。(-_-;)
このページでは、作成したスクリプトの紹介と、実際に関数式のあてはめを実施するときのコツなどを紹介する。
なお、最初に申し上げるが、最初はがんばってTree構造を使って、個体(遺伝子)を生成したが、交配(交叉)や突然変異は、Tree構造の関数式を文字列として行っているので、プログラミング的にはまったく参考にならない。あらかじめご了承を。m(_ _)m
遺伝的プログラミングとは
遺伝的プログラミングは、遺伝的アルゴリズムと良く似た手法で解を求める手法。
遺伝的アルゴリズムは、ナップサック問題(ナップサックの中に効率的に荷物を詰め込む問題)に代表されるもので、ある荷物を入れるか入れないかで体積の増減を決まった値でしか変動させることしかできない。
一方、遺伝的プログラミングは、体積など固有の値だけでなく、変数や条件式をいれることができるので、より複雑な解を求めることができるようだ。
以下のサイトに非常にわかりやすく解説されていたので参照を。
手法は、まずは個体(遺伝子)を作成し、評価関数により個体を評価する。
続いて、評価により優秀な個体を中心に、他の優秀な個体と交配(交叉)させる。
また、自然界と同様にある頻度で、突然変異も起こさせて、さらに優秀な個体、言い換えれば優良な解を得やすくするアルゴリズム。
作成したプログラム
実際に、作成したプログラムは以下のとおり。
rubyの開発環境がある方は、リンク先のrubyスクリプトをダウンロードして実行を。
$ mv geneprg.rb.txt geneprg.rb $ chmod +x geneprg.rb & ./geneprg.rb
また、サンプルデータもダウンロードして、rubyスクリプトと同じフォルダに保存する。
ちなみに、データファイルは、以下のようにxの値とyの値を[,](カンマ)で区切って記述し、データは前述のインターフェースの記事のものを流用させていただいた(多謝)。
# x の値 , y の値 # 解 y = -3 x^4 + 4 x^3 + 12 x^2 # 行頭の#はコメント行 -3, -243 -2, -32 -1, 5 0, 0 1, 13 2, 32 3, -27 4, -320
rubyスクリプトのソース (本来は、お見せできるレベルのものではないが… (^^ゞ)
#!/usr/bin/env ruby # -*- encoding: utf-8 -*- # generuby.rb # 遺伝的プログラミングの実装テスト # 最適な関数を探す # ver 0.01 2019-01-23 start - 2019-02-13 # ver 0.04 2019-02-22 データファイル読み込み、NaN対策 # =begin Interface CQ出版社 2018年3月号 「人工知能アルゴリズム探索隊」より y = -3x^4 + 4x^3 + 12x^2 $x = [ -3, -2, -1, 0, 1, 2, 3, 4] $y = [-243, -32, 5, 0, 13, 32, -27, -320] Node と Leaf の2種類がある Node のタイプ + - * / ^ Leaf のタイプ x 0〜10の数値 (左右2つを必ず持つ) tree は node を一つ以上もち、leaf を2つ持つ leaf は、nodeの場合とleafの場合がある =end $KCODE = "UTF8" if RUBY_VERSION < '1.9.0' require 'rubygems' # 定数(パラメータ)定義 MAX_DEPTH = 20 # 階層の深さ POPULATION = 2000 # 1世代当たりの個体数 MUTATION_RATE = 0.1 # 突然変異率 MATE_RATE = 0.4 # 交配対象の率 例 上位6割まで MAX_CROSS_RATE = 0.3 # 交配率 MAX_GENERATION = 500 # 最大世代数 $max_cross = POPULATION * MAX_CROSS_RATE # 最大交配組合せ数 交配後の個体はその2倍 $mate_num = POPULATION* MATE_RATE # 交配の相手となり得る個体 例)上位30まで $max_mutation = POPULATION * MUTATION_RATE # 突然変異を起こす個体数 # node の種類と確率 合計100になるように ^ は ruby では ** #$node_hash = { "+" => 24, "-" => 24, "*" => 24, "/" => 24, "^" => 4 } $node_hash = { "+" => 25, "-" => 25, "*" => 25, "/" => 25 } # leaf の種類と確率 合計100になるように i の場合は 9までの整数 $leaf_hash = { "x" => 25, "n" => 25, "i" => 50 } # max_depth のときの leaf の種類と確率 合計100になるように i の場合は 9までの整数 $max_depth_leaf_hash = { "x" => 25, "i" => 75 } USAGE = <<'EOS' [Usage] geneprg.rb datafile.txt dataファイルを指定しない場合は、カレントディレクトリの gp_data.txtを用いる datafile フォーマット # 先頭行の#はコメント data_x1, data_y1 data_x2, data_y2 data_x3, data_y3 EOS # x と y の値 $x = Array.new $y = Array.new # hash を受けて、確率に基づく文字を返す def prob_ch(m_hash) range_hash = Hash.new() sum = 0 m_hash.each{ |key, value| sum += value range_hash[key] = sum } num = rand(sum) range_hash.each{ | key, value | if num < value return key end } end class Tree attr_accessor :node_value # node の 演算子 attr_accessor :lleaf # node の 左下 leaf attr_accessor :rleaf # node の 右下 leaf attr_accessor :sqerr # 誤差の二乗和 attr_accessor :funcstr # 関数の文字列 def initialize @node_value = prob_ch($node_hash) @lleaf = prob_ch($leaf_hash) @lleaf = rand(10) if @lleaf == "i" @rleaf = prob_ch($leaf_hash) @rleaf = rand(10) if @rleaf == "i" @sqerr = 0.0 @funcstr = "" end end def make_tree(depth) tree = Tree.new while tree.lleaf == "n" || tree.rleaf == "n" if depth == MAX_DEPTH tree.lleaf = prob_ch($max_depth_leaf_hash) tree.lleaf = rand(10) if tree.lleaf == "i" tree.rleaf = prob_ch($max_depth_leaf_hash) tree.rleaf = rand(10) if tree.rleaf == "i" break end tree.lleaf = make_tree(depth) if tree.lleaf == "n" tree.rleaf = make_tree(depth) if tree.rleaf == "n" depth += 1 end return tree end # function を string に # 各項間にスペース def func_str(t) str = "(" if t.lleaf.class == Tree str += " " + func_str(t.lleaf) else str += " " + t.lleaf.to_s end str += " " + t.node_value if t.rleaf.class == Tree str += " " + func_str(t.rleaf) else str += " " + t.rleaf.to_s end str += " " + ")" return str end def calc_sqerr(value, y) return (value - y)**2 end # 力技で、指定する()を切り取る def cut_func(str, cutp) fn = [ "", "", "" ] # 0: pre 1: match 2: after i_num = v_num = 0 # cutp ( num v_num ()の増減 inflag = "p" # [p] pre [m] match [a] after str.scan(/./){|ch| case ch when "(" then if i_num == cutp inflag = "m" i_num += 1 fn[1] += ch # match else case inflag when "p" i_num += 1 fn[0] += ch when "m" v_num += 1 fn[1] += ch else fn[2] += ch end end when ")" then case inflag when "p" fn[0] += ch when "m" fn[1] += ch inflag = "a" if v_num == 0 v_num -= 1 else fn[2] += ch end else case inflag when "p" fn[0] += ch when "m" fn[1] += ch else fn[2] += ch end end } return fn end # 初期個体の生成 def init_tree(tree) num = 0 while num < POPULATION tree[num] = make_tree( 0 ) tree[num].funcstr = func_str(tree[num]) #next if tree[num].funcstr.count("(") < 2 if tree[num].funcstr.match('x') num += 1 #p "OK" else next end end return tree end # ソート def sort_tree(tree) tree = tree.sort{|a, b| a.sqerr <=> b.sqerr} return tree end # cross def cross_tree(tree) for i in 0...$max_cross do # max_crossの数は含まない max_cross - 1 j = rand($mate_num) i_node, j_node = tree[i].funcstr.count("("), tree[j].funcstr.count("(") funcstr1 = funcstr2 = "" icutp, jcutp = rand(i_node), rand(j_node) p1 = cut_func(tree[i].funcstr, icutp) p2 = cut_func(tree[j].funcstr, jcutp) funcstr1 = p1[0] + p2[1] + p1[2] funcstr2 = p2[0] + p1[1] + p2[2] while funcstr1.count("(") > MAX_DEPTH * 2 funcstr1 = funcstr1.sub(/\([!-~ ]{7}\)/, rand(10).to_s) end while funcstr2.count("(") > MAX_DEPTH * 2 funcstr2 = funcstr2.sub(/\([!-~ ]{7}\)/, rand(10).to_s) end tree[POPULATION - 1 - 2 * i ].funcstr = funcstr1 tree[POPULATION - 1 - 2 * i - 1].funcstr = funcstr2 end return tree end # 突然変異 def mute_tree(tree) for i in 0...($max_mutation) do j = rand(POPULATION) chnum = tree[j].funcstr.scan(/\d+|x/).length mp = rand(chnum) atree = make_tree(MAX_DEPTH) atree.funcstr = func_str(atree) rfunc = "" cnt = 1 tree[j].funcstr.scan(/./){ |ch| if ch =~ /\d+/ || ch == "x" if cnt == mp rfunc += atree.funcstr else rfunc += ch end cnt += 1 else rfunc += ch end } tree[j].funcstr = rfunc return tree end end # 2乗和の計算 def sum_sqerr(fstr) fvalue = sqerr = 0 for i in 0...$x.length do fxstr = fstr.gsub(/x/, "#{$x[i].to_s}").gsub(/\^/, "**") begin fvalue = eval("#{fxstr}") fvalue = Float::INFINITY if fvalue.nan? rescue => e s = Float::INFINITY # 無限大 end sqerr += calc_sqerr(fvalue.to_f, $y[i]) end return sqerr end # main loop # 最大 loop 回数になるまで実行 def main() if ARGV.size == 0 dfile = "gp_data.txt" elsif ARGV[0].to_s == "-h" || ARGV[0].to_s == "-help" puts USAGE exit else dfile = ARGV[0].to_s end File.open("#{dfile}"){ |f| while line = f.gets next if line[0] == "#" || !line.index(/[0-9]/) line = line.rstrip.split(",") $x.push(line[0].to_f) $y.push(line[1].to_f) end } tree = Array.new(POPULATION) tree = init_tree(tree) tree.each { | t | t.sqerr = sum_sqerr(t.funcstr) } tree = sort_tree(tree) i = 1 until i > MAX_GENERATION do tree = cross_tree(tree) tree = mute_tree(tree) tree.each { | t | t.sqerr = sum_sqerr(t.funcstr) } tree = sort_tree(tree) print i, " times ", tree[0].sqerr, " : ", tree[0].funcstr, "\n" break if tree[0].sqerr == 0.0 i += 1 end print tree[0].sqerr, " : ", tree[0].funcstr, "\n" end if __FILE__ == $0 main end
実行すると、その世代のトップの個体の2乗和(ばらつき)とその数式が表示される。
1 times 100400.0 : ( ( 2 - 7 ) * ( x * x ) ) (中略) 50 times 902.72 : ( ( ( ( ( ( ( x * ( 3 - x ) ) - ( x * x ) ) * ( x * x ) ) * 1 ) - ( ( ( 3 - x ) * x ) - 6 ) ) + ( ( 3 - x ) * 2 ) ) - ( ( ( x * ( ( ( ( ( ( ( ( x * x ) - 7 ) - 6 ) * x ) * 1 ) / 5 ) * x ) - 6 ) ) - 8 ) * 1 ) ) (中略) 96 times 0.0 : ( ( ( ( ( ( x * ( 3 - x ) ) - ( x * x ) ) * ( x * x ) ) - ( ( ( ( ( ( x * x ) - 7 ) - 6 ) * x ) * x ) - ( x * x ) ) ) - ( x * ( 3 - x ) ) ) + ( x * ( ( 3 - x ) - ( ( 2 - x ) * x ) ) ) )
上記の例では、96世代目で解に到達したが、解に到達できないことが多い。
筆者が行った数少ない経験から、解に到達する確率を上げる方法について、次節で述べる。
Tips
これまでの経験から、解に到達する上で、重要と感じられたパラメータを以下に示す。
・1世代あたりの個体数 ⇒ 個体数が多いほど、解に到達しやすい
POPULATION = 2000 # 1世代当たりの個体数
・ 階層の深さ ⇒ ある程度深い方が、解に到達しやすい
MAX_DEPTH = 20 # 階層の深さ
・ 交配率が高いほど、解に到達しやすい
MAX_CROSS_RATE = 0.3 # 交配率
・ 世代は多い方が、解に到達しやすい
MAX_GENERATION = 500 # 最大世代数
いずれにしても、スクリプトの最初の方にあるパラメータを変化させてチャレンジしてみて。
というのも、遺伝的プログラミングは、局所解に陥りやすい特徴があるため、パラメータの調整は、必須だと思って。
得られた解が、カッコが多くて非常に読みにくいが、Raspberry Pi等をお持ちの場合は、Walform Mathematicaが付属しているので、下図のようにExpandコマンドで簡単に式を展開することができる。

この例では、もともとの式が y = -3 x^4 + 4 x^3 + 12 x^2 だったが、式を展開してみてもバッチリ正解だった。
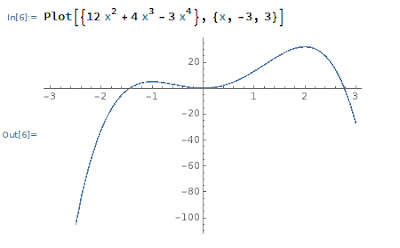
なお、Mathematica は、流石に高級なソフトウェアだけあって、きれいにグラフを描いてくれる。
例えば、y = -3 x^4 + 4 x^3 + 12 x^2 をグラフにするときは、以下のとおり Plot コマンドを用いる。
Plot[ { -3 x^4 + 4 x^3 -12 x^2}, {x, -3, 3}] # xを -3から+3まで変化させる
おわりに
足早だったが、ひととおり遺伝的プログラミングについて解説した。
くどいようだが、このアルゴリズムは、局所解に陥りやすいので、パラメータを変更して何度も試してみること。
その際に、Mathematicaのようにグラフ化すると、イメージがつかみやすくて良い。
また、何かわかりましたら、記述するね。

